z:http://www.wojilu.com/forum1/topic/2235
github 使用 ssh 方式认证登录。
官方文档:http://help.github.com/ssh-key-passphrases/
之所以不使用普通的密码验证登录,原因在于:密码不够安全。如果你使用简单的密码,比如“1234”,非常容易被猜到或者被暴力破解;如果你使用复杂的密码,为了避免自己也忘记,又可能会记在某个地方,如果被人发现,就糟了。两种方式都很不妥。所以 github 采用 ssh 密钥方案。
但如果只使用 ssh 密钥而不使用 passphrase(口令或密码),那跟使用复杂密码然后记下来没啥区别。比如你将ssh密钥记在电脑某处,如果其他人获取了这个文件,那就没有安全可言。解决办法是:再增加一个 passphrase。
所以,整个认证过程是:
a)先生成一个 ssh key,在github和本地机器配置;
b)然后在登录的时候,再输入 passphrase 登录(当然,我们可以通过脚本配置,避免每次重复输入 passphrase )。
第一部分:配置ssh
先进入 cygwin 命令行。为了在你的电脑和github之间建立安全连接,需要SSH keys,所以你需要
1)先检测是否有这个key,请点击开始菜单中的 Git Bash,输入如下命令
$ cd ~/.ssh
2)系统应该反馈“系统找不到指定文件”,那么,我们需要生成一个新的key,输入如下代码
$ ssh-keygen -t rsa -C “your_email@youremail.com”
——其中的email请填写你注册时候的email
系统开始生成ssh公钥和私钥,然后会问你保存的目录,请直接回车即可(直接回车意味着在当前目录下的.ssh目录保存)。
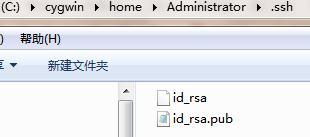
3)输入一个密码(passphrase),请至少填写一个4位数,这个密码是你连接到github所用。输入之后,会生成id_rsa(私钥) 和 id_rsa.pub(公钥) 文件,如下图所示:
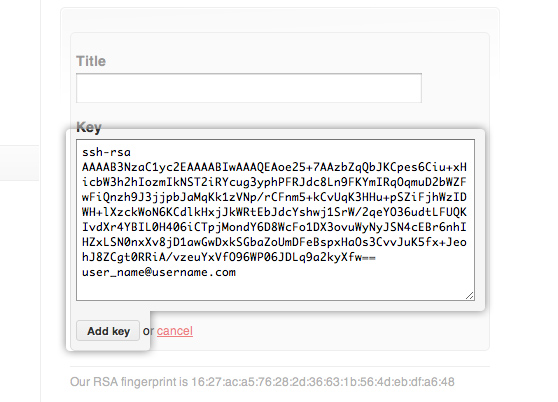
访问github网站, “Account Settings” > Click “SSH Public Keys” > Click “Add another public key”
用文本编辑器打开上图中第二个文件 id_rsa.pub,里面的内容就是SSH key,请复制它,粘贴入key里面,记得不要有任何多余的空格和换行。然后点击“Add key”提交。(Title栏可以不填写)
现在,你可以测试通过SSH连接到github了。请打开Git Bash,输入如下代码——
ssh -T git@github.com
如果提示“can’t be established.”什么东西(如下代码),请不要管,直接按yes
The authenticity of host ‘github.com (207.97.227.239)’ can’t be established.
RSA key fingerprint is 16:27:ac:a5:76:28:2d:36:63:1b:56:4d:eb:df:a6:48.
Are you sure you want to continue connecting (yes/no)?
然后提示输入密码(passphrase)。
如果看到 You’ve successfully authenticated, but GitHub does not provide shell access 信息,就表示连接成功。
第二部分:避免重复输入 passphrase
通过上面的流程,已经正确配置了 ssh ,但你每次使用的时候,总是很不爽,比如在命令行下,每次 pull 或 push,都要重复输入 passphrase。你会想:我明明已经使用 ssh key 了,为什么还要我输入密码?
分两种情况讨论——
一、命令行下避免重复输入
在这种情况下,有一个工具可以帮你避免重复输入 passphrase ,这个工具叫 ssh-agent ,它可以帮你安全的存储passphrase,不用重复输入。
具体使用方法是通过脚本预设——
1)打开用户主目录下(比如c/cygwin/home/Administrator)的 .bashrc 文件,将如下脚本内容添加进去:
SSH_ENV=”$HOME/.ssh/environment”
start the ssh-agent
function start_agent {
echo “Initializing new SSH agent…”
spawn ssh-agent
ssh-agent | sed ‘s/^echo/#echo/‘ > “$SSH_ENV”
echo succeeded
chmod 600 “$SSH_ENV”
. “$SSH_ENV” > /dev/null
ssh-add
}
test for identities
function test_identities {
test whether standard identities have been added to the agent already
ssh-add -l | grep “The agent has no identities” > /dev/null
if [ $? -eq 0 ]; then
ssh-add
$SSH_AUTH_SOCK broken so we start a new proper agent
if [ $? -eq 2 ];then
start_agent
fi
fi
}
check for running ssh-agent with proper $SSH_AGENT_PID
if [ -n “$SSH_AGENT_PID” ]; then
ps -ef | grep “$SSH_AGENT_PID” | grep ssh-agent > /dev/null
if [ $? -eq 0 ]; then
test_identities
fi
if $SSH_AGENT_PID is not properly set, we might be able to load one from
$SSH_ENV
else
if [ -f “$SSH_ENV” ]; then
. “$SSH_ENV” > /dev/null
fi
ps -ef | grep “$SSH_AGENT_PID” | grep -v grep | grep ssh-agent > /dev/null
if [ $? -eq 0 ]; then
test_identities
else
start_agent
fi
fi
2)然后打开 cygwin 的命令行,第一次打开,它会要求你输入 passphrase ,输入之后,再执行相应的远程操作,就不会要求重复输入 passphrase 了(当然重启电脑会要求再次输入)。
二、git extentions 中避免重复输入
【启用 PuTTY】
1)打开 PuTTY,方法:“远程”->PuTTY->“生成或者导入key”
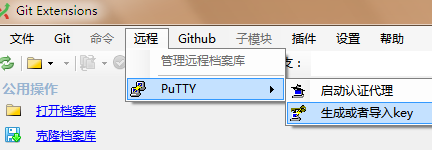
2)导入你前面的 ssh key,点击下面的“Load”按钮,导入前面生成的 id_rsa 文件(注意:是id_rsa,没有后缀名,不是id_rsa.pub)
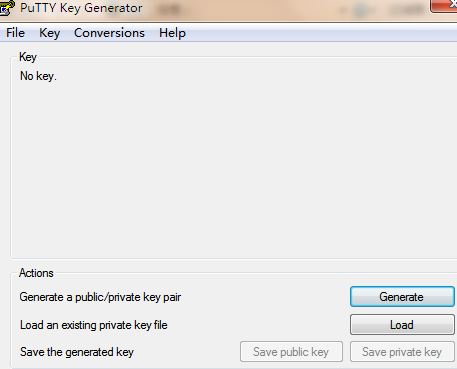
3)这时它要求你输入 passphrase
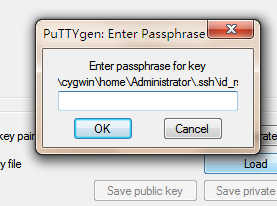
4)输入成功,然后你需要点击下图的 Save private key,将私钥保存,你可以将它保存在 id_rsa(ssh私钥) 同一个目录。PuTTY 生成的私钥文件是 .ppk 后缀名。

【在 git extensions 中使用 PuTTY】
1)打开 git etensions,在 “远程”菜单中,点击“管理远程档案库”
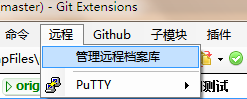
2)点击右下部分的“私钥文件”后面的“浏览”,将前面 PuTTY 中保存的 .ppk 后缀的私钥文件加载进来。
然后点击“加载SSH密钥”,输入 passphrase,然后点击“测试连接”

此时 PuTTY/plink.exe 开始启动,只要这个开着,就不用重复输入 passphrase
3)现在可以顺利和远程库操作,比如下面的“拉取”
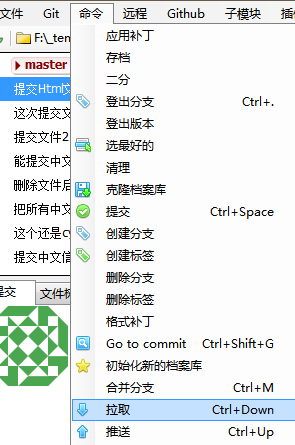
或者在 vs 中直接操作——